How Google Evaluates AI Content Systems
Quick Answer
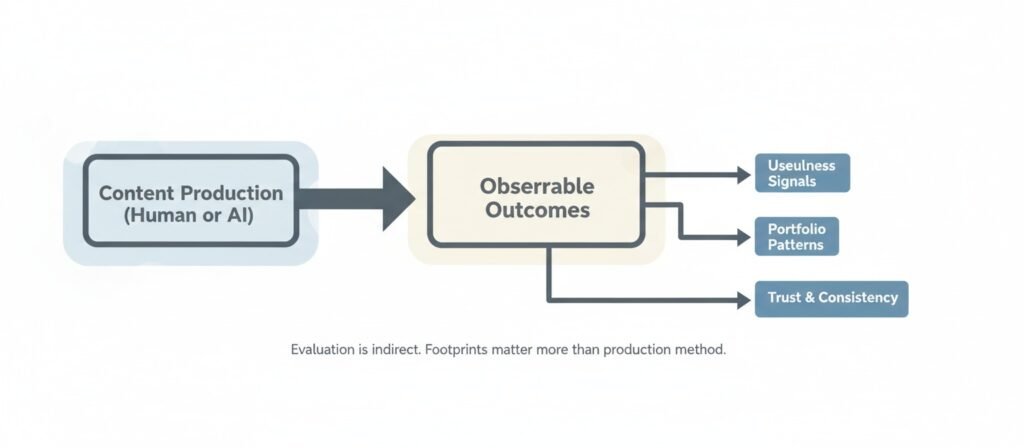
Google does not evaluate “AI content” as a separate category It evaluates observable outcomes. Search systems do not need a reliable AI detector to rank pages. They observe usefulness, originality signals, consistency, and trust-related patterns. When automation creates repetitive, low-differentiation portfolios, rankings tend to weaken. When automation operates inside structured validation and accountability, outcomes may remain stable.
“Some AI ranks” and “some AI drops” can both be true — because the evaluation target is not the writing tool. It is the system footprint.
Does Google penalize AI content?
Google does not automatically penalize AI-generated content. It evaluates usefulness, originality, trust signals, and system-level patterns rather than the production tool itself.
This article explains that footprint.
Introduction: The Mismatch
Public discussion around AI content often begins with a simplified claim: Google does not penalize AI-generated content. That statement is directionally consistent with Google’s published guidance. The official position emphasizes rewarding high-quality content regardless of how it is produced.
However, this framing often leaves practitioners confused. If AI is not penalized, why do some large-scale AI-driven sites decline after updates? Why do monetization reviews cite “low value content” even when grammar and structure appear correct?
These declines often follow the patterns we documented in why AI websites fail after launch—not because individual pages are flawed, but because the system-level footprint triggers evaluation thresholds.
The tension emerges from a unit mismatch. Most debates focus on single pages. Search systems, however, tend to observe patterns across portfolios.
This article analyzes evaluation at the system level, not at the sentence level. It does not discuss detector bypass techniques, ranking tricks, or tactical SEO advice. The goal is to describe mechanisms and structural signals.
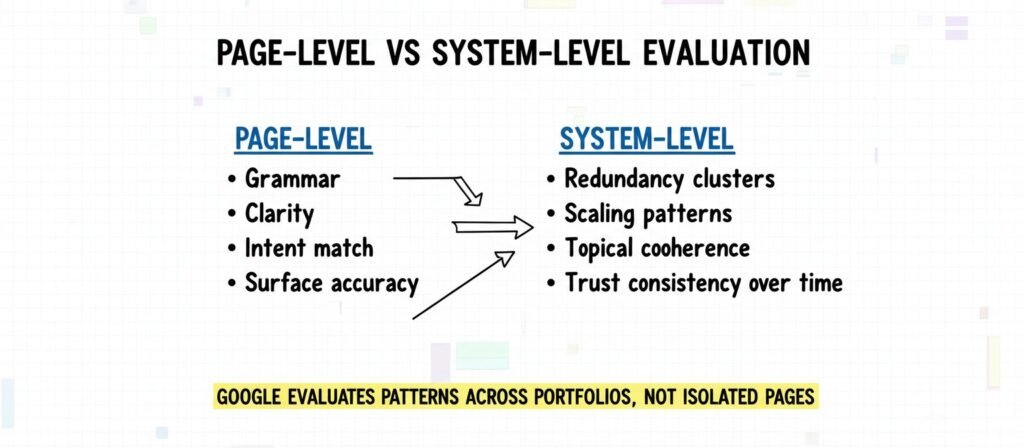
The Unit Problem: Why “AI Content” Is the Wrong Target
Pages Are Artifacts; Systems Produce Portfolios
A page is an artifact. A content system is a production model. When automation is introduced, it rarely produces one page. It produces clusters: topic expansions, long-tail variants, template-driven structures, or rapid publication bursts. These patterns create statistical signatures across a domain.
Search evaluation systems are designed to detect patterns over time. A single fluent article does not necessarily define how a domain behaves. A hundred similar articles may.
In this sense, the relevant unit is not “Was this page written by AI?” but “What behavior does this portfolio exhibit?”
This portfolio-level pattern is precisely what we analyzed in AI content cannibalization issues—multiple pages competing for the same intent create a statistical signature that evaluation systems can observe.
“Who, How, and Why” as Proxies
Google’s documentation often encourages evaluating content based on who created it, how it was created, and why it was created. These are not literal AI detection switches. They function as evaluative lenses.
The system does not need to know whether a language model was used. It evaluates signals that correlate with usefulness, originality, and trust. The production method becomes indirectly visible through outcomes.
Evaluation Surfaces: Where Systems Leave Footprints
Evaluation appears to operate across multiple surfaces.
Page-Level: Usefulness and Clarity
At the page level, clarity, relevance, and comprehensiveness matter. This includes answering user intent directly and avoiding misleading or fabricated claims. However, page-level fluency is a baseline, not a guarantee. Many AI-generated pages meet grammatical and structural standards.
The differentiation occurs elsewhere.
Site-Level: Scaling Signatures
Automation tends to introduce repeatable structures. These may include:
- Near-identical headings across multiple pages
- Predictable phrasing patterns
- Thin expansions of closely related keywords
- Rapid bursts of publication without proportional depth
These signals do not automatically imply spam. However, when they correlate with low differentiation and low information gain, performance may weaken.
This weakening explains why AI blogs get stuck at zero impressions despite consistent publishing—the scaling signatures accumulate without corresponding value signals.
Google’s spam policy documentation explicitly addresses scaled content abuse, particularly where automation is used to generate large volumes of low-value material.
This policy directly applies to the patterns we observed in autoblogging environments, where volume increases without structural differentiation trigger exactly these abuse signals.
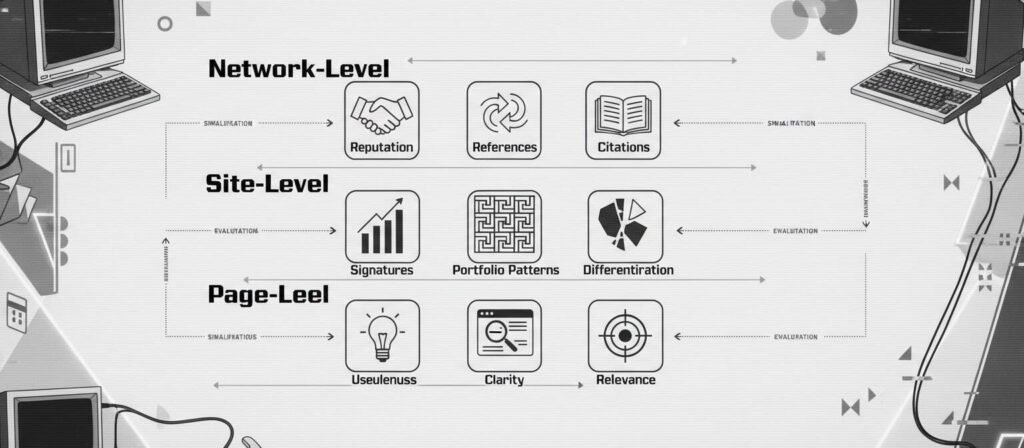
Network-Level: Reputation and Reference Environment
Trust is rarely built in isolation. External references, citations, mentions, and brand-level recognition influence how content is perceived in the broader web ecosystem.
E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) is not a sentence-level property. It emerges through consistency and corroboration across time.
The Search Quality Rater Guidelines provide insight into how evaluators assess credibility signals, particularly for sensitive topics.
“People-First” as a System Constraint
Google’s helpful content system emphasizes people-first principles. This is sometimes interpreted as a stylistic instruction. Structurally, it functions as a constraint on production models.
Helpfulness as Observable Behavior
Helpfulness can manifest through:
- Specificity rather than generic summaries
- Evidence or real-world framing
- Clear resolution of intent
These are observable behaviors. They are not dependent on whether a human or AI drafted the initial text.
Information Gain vs Surface Fluency
AI systems often summarize existing information effectively. Summarization, however, does not always produce new value.
Information gain — adding perspective, data, synthesis, or structured clarity — may differentiate content that sustains visibility from content that blends into existing results.
Grammatical correctness alone does not guarantee competitive strength.
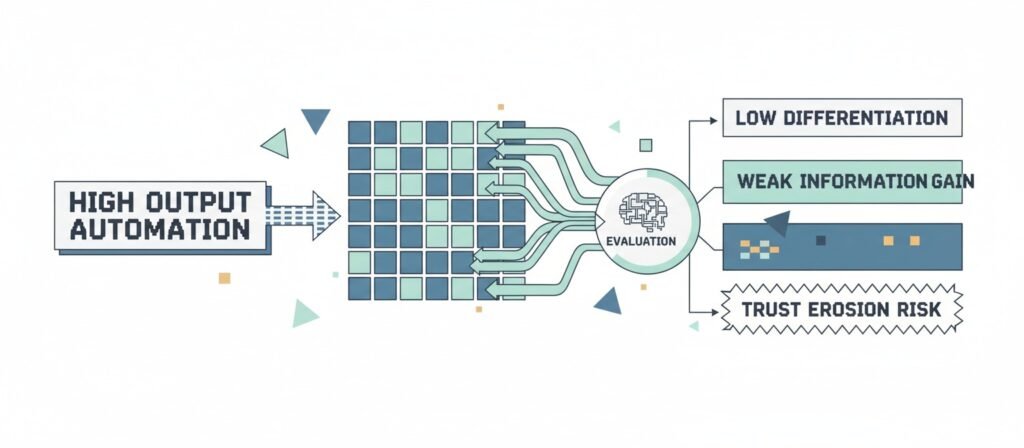
Common Failure Modes in AI Content Systems
Template Repetition
When multiple pages follow identical structural scaffolding with minimal conceptual variation, redundancy increases. Redundancy may correlate with weaker differentiation.
This redundancy is a structural driver of the cannibalization patterns documented in AI content cannibalization issues—identical scaffolding produces pages that evaluation systems cannot distinguish by intent.
Scaled Content Abuse as a Production Model
Google’s official guidance states that scaled content production designed primarily for ranking manipulation violates spam policies.
The risk is not automation itself. The risk emerges when throughput increases while validation, oversight, and originality remain flat.
This flat oversight is why why automated content doesn’t compound—throughput without validation produces accumulation, not authority.
Weak Correction Mechanisms
AI systems can produce confident inaccuracies. If a content system lacks review loops, updates, or correction mechanisms, trust signals may degrade over time.
This degradation explains why AI content sites getting no-index after publishing often have no recovery path—without correction mechanisms, initial indexing failures become permanent.
Trust is often reinforced through correction capacity, not initial perfection.
Mapping Public Confusion to Structural Reality
Public discourse frequently centers on detection anxiety:
- “Does Google detect AI?”
- “If I rewrite it in my own words, is it safe?”
- “Why was my AdSense rejected for low value content?”
These questions treat evaluation as a binary gate.
These rejections often trace back to the portfolio-level patterns we documented in why AI blogs get no traffic—the system observes a site-wide footprint, not individual page quality.
In practice, evaluation appears to be gradient-based and outcome-driven. Some AI-driven sites rank successfully. Others decline. Context, niche competition, differentiation, and portfolio coherence all influence results. Contradictory anecdotes can coexist because the evaluation surface is multidimensional.
The Core Model: Indirect Evaluation
What Google Cannot Reliably Know
Search systems cannot always determine the exact production tool used. Tool detection is not necessary for ranking decisions.
What Google Can Observe
Observable signals may include:
- Redundancy patterns across clusters
- Topical depth and coherence
- Consistency in claims and citations
- Update behavior over time
- Engagement signals that correlate with perceived usefulness
Google’s public documentation on how search works emphasizes ranking systems that evaluate relevance and quality through multiple signals. The system evaluates effects. Causes are inferred through patterns.
Why Opposite Outcomes Can Both Be True
In low-competition niches, AI-generated content may perform adequately if it satisfies intent and avoids redundancy. In saturated niches, identical summarization may struggle.
The production method is constant. The surrounding system conditions vary.

Frequently Asked Questions:
Does Google detect AI content?
Google has stated that it focuses on quality rather than origin. There is no publicly confirmed simple “AI switch.” Evaluation appears outcome-based.
If I rewrite AI output in my own words, is it safe?
Rewriting may change phrasing, but if the underlying information remains generic or duplicative, differentiation may remain limited. Evaluation focuses on value, not paraphrasing alone.
Why does AdSense sometimes flag “low value content”?
Monetization reviews may consider originality, depth, and differentiation. Large portfolios of thin or repetitive pages may correlate with low-value assessments.
Are AI videos or text-to-speech content treated differently?
Medium alone does not determine quality. Usefulness, trust, and differentiation remain central evaluation themes.
What does “quality” actually mean?
In structural terms, quality often involves specificity, accuracy, consistency, and meaningful contribution beyond existing summaries.
Conclusion: From Writing Quality to System Design Quality
The debate over AI content often centers on tools. Search evaluation appears to center on patterns. Google’s published guidance consistently emphasizes rewarding high-quality content regardless of production method.
However, automation changes portfolio behavior. That behavior leaves footprints.
When automation amplifies redundancy, thin expansion, or weak oversight, performance may weaken. When automation operates within validation, differentiation, and accountability constraints, outcomes may remain stable.
The evaluation target is not the tool. It is the system that uses it.
External References
- Google Search and AI-Generated Content
https://developers.google.com/search/blog/2023/02/google-search-and-ai-content - Helpful Content System Guidance
https://developers.google.com/search/docs/fundamentals/creating-helpful-content - Search Quality Rater Guidelines (PDF)
https://static.googleusercontent.com/media/guidelines.raterhub.com/en//searchqualityevaluatorguidelines.pdf - Spam Policies (Scaled Content Abuse)
https://developers.google.com/search/docs/essentials/spam-policies - How Search Works
https://www.google.com/search/howsearchworks/
